Elasticsearch中文分词
elasticsearch默认分词器比较坑,中文的话,直接分词成单个汉字。
我们这里来介绍下smartcn插件,这个是官方推荐的,中科院搞的,基本能满足需求;
还有另外一个IK分词器。假如需要自定义词库的话,那就去搞下IK,主页地址:https://github.com/medcl/elasticsearch-analysis-ik
smartcn安装比较方便,
直接用 elasticsearch的bin目录下的plugin命令;

先进入elasticsearch的bin目录
然后执行 sh elasticsearch-plugin install analysis-smartcn
-> Downloading analysis-smartcn from elastic
[=================================================] 100%
-> Installed analysis-smartcn
下载 自动安装;
(注意,假如集群是3个节点,所有节点都需要安装;不过一般都是先一个节点安装好所有的东西,然后克隆几个节点,这样方便)
安装后 plugins目录会多一个smartcn文件包;
安装后,我们需要重启es;
然后我们来测试下;
Post http://192.168.195.131:9200/_analyze/
{"analyzer":"standard","text":"我是中国人"}
执行标准分词器;

中文都是单个字了,很不符合需求;
我们用下 smartcn;
{"analyzer":"smartcn","text":"我是中国人"}
执行结果:

我们发现 中国 编程个单个词汇;
我们新建索引film2
然后映射的时候,指定smartcn分词;
Post http://192.168.195.131:9200/film2/_mapping/new/
{
"properties": {
"title": {
"type": "text",
"analyzer": "smartcn"
},
"publishDate": {
"type": "date"
},
"content": {
"type": "text",
"analyzer": "smartcn"
},
"director": {
"type": "keyword"
},
"price": {
"type": "float"
}
}
}
然后执行前面的数据代码;
这样前面film索引,数据是标准分词,中文全部一个汉字一个汉字分词;film2用了smartcn,根据内置中文词汇分词;
package com.javaxl.elasticsearch;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.net.InetAddress;
/**
* @author 小李飞刀
* @site www.javaxl.com
* @company
* @create 2019-10-15 16:17
*
* 中文分词器smartcn讲解
*/
public class Demo5 {
private static String host="192.168.195.129"; // 从节点服务器地址
private static int port=9300; // 端口(注意:这里是9300不是9200,Java连接elasticsearch是9300)
public static final String CLUSTER_NAME="my-application"; // 集群名称
private static Settings.Builder settings=Settings.builder().put("cluster.name",CLUSTER_NAME);
private TransportClient client=null;
private static final String ANALYZER="smartcn";
@SuppressWarnings({ "resource", "unchecked" })
@Before
public void getCient()throws Exception{
client = new PreBuiltTransportClient(settings.build())
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(host),port));
}
/**
* 关闭连接
*/
@After
public void close(){
if(client!=null){
client.close();
}
}
/**
* 创建索引 添加文档
* @throws Exception
*/
@Test
public void testIndex()throws Exception{
JsonArray jsonArray=new JsonArray();
JsonObject jsonObject=new JsonObject();
jsonObject.addProperty("title", "哪吒之魔童降世");
jsonObject.addProperty("publishDate", "2019-07-26");
jsonObject.addProperty("content", "天地灵气孕育出一颗能量巨大的混元珠,元始天尊将混元珠提炼成灵珠和魔丸,灵珠投胎为人,助周伐纣时可堪大用;而魔丸则会诞出魔王,为祸人间。元始天尊启动了天劫咒语,3年后天雷将会降临,摧毁魔丸。太乙受命将灵珠托生于陈塘关李靖家的儿子哪吒身上。然而阴差阳错,灵珠和魔丸竟然被掉包。本应是灵珠英雄的哪吒却成了混世大魔王。调皮捣蛋顽劣不堪的哪吒却徒有一颗做英雄的心。然而面对众人对魔丸的误解和即将来临的天雷的降临,哪吒是否命中注定会立地成魔?他将何去何从?");
jsonObject.addProperty("director", "饺子");
jsonObject.addProperty("price", "35");
jsonArray.add(jsonObject);
JsonObject jsonObject2=new JsonObject();
jsonObject2.addProperty("title", "寄生虫");
jsonObject2.addProperty("publishDate", "2019-10-11");
jsonObject2.addProperty("content", "《寄生虫》讲述一家四口全是无业游民的爸爸基泽(宋康昊饰)成天游手好闲,直到积极向上的长子基宇(崔宇植饰)靠着伪造的文凭来到富豪朴社长(李善均饰)的家应征家教,两个天差地远的家庭因而被卷入一连串意外事件中");
jsonObject2.addProperty("director", "奉俊昊");
jsonObject2.addProperty("price", "45");
jsonArray.add(jsonObject2);
JsonObject jsonObject3=new JsonObject();
jsonObject3.addProperty("title", "送我上青云");
jsonObject3.addProperty("publishDate", "2019-08-16");
jsonObject3.addProperty("content", "《女记者盛男(姚晨饰),心高气傲,个性刚硬,渴望真爱仍孑然一身,怀抱理想却屡屡在现实中碰壁。盛男意外地患上了卵巢癌,为了筹得手术费,她不得不接受一份自己不喜欢的工作,为一位企业家的父亲写自传,也因此踏上一段寻求爱欲亦是寻找自我的旅程。");
jsonObject3.addProperty("director", "滕丛丛");
jsonObject3.addProperty("price", "55");
jsonArray.add(jsonObject3);
JsonObject jsonObject4=new JsonObject();
jsonObject4.addProperty("title", "复仇者联盟4");
jsonObject4.addProperty("publishDate", "2019-04-14");
jsonObject4.addProperty("content", "来自泰坦星的灭霸(乔什·布洛林饰)为了解决宇宙资源匮乏、人口暴增的问题,集齐6颗无限宝石,一个响指让全宇宙生命公平随机的减半。宇宙由于疯狂的泰坦灭霸的行动而变得满目疮痍,在泰坦星与灭霸决战失败的钢铁侠(小罗伯特·唐尼饰)孤身一人漂流宇宙,迷失在量子领域的蚁人(保罗·路德饰)意外回到现实世界,他的出现为幸存的复仇者们点燃了希望。无论前方将遭遇怎样的后果,幸存的超级英雄们都必须在剩余盟友的帮助下再一次集结,以逆转灭霸的所作所为,彻底恢复宇宙的秩序。");
jsonObject4.addProperty("director", "乔·罗素安东尼·罗素");
jsonObject4.addProperty("price", "35");
jsonArray.add(jsonObject4);
JsonObject jsonObject5=new JsonObject();
jsonObject5.addProperty("title", "蜘蛛侠:英雄远征");
jsonObject5.addProperty("publishDate", "2019-06-28");
jsonObject5.addProperty("content", "在复仇者联盟众英雄的努力下,于灭霸无限手套事件中化作为灰烬的人们,重新回到了人世间,曾经消失的蜘蛛侠 彼得帕克 也回归到了普通的生活之中,数月后,蜘蛛侠彼得帕克所在的学校举行了欧洲旅游,帕克也在其中, 在欧州威尼斯旅行时,一个巨大无比的水怪袭击了威尼斯,不敌敌人的蜘蛛侠幸得一位自称神秘客的男子搭救才击退敌人,之后 神盾局局长找上正在旅游的彼得帕克并要求其加入神盾局,并安排神秘客协助帕克,神秘客自称来自其他宇宙,并告知一群名为元素众的邪恶势力已经入侵这个宇宙了,为了守护来之不易的和平,蜘蛛侠决定与神秘客联手,然而在神秘客那头罩之中,似乎隐藏着什么不为人知的真相……");
jsonObject5.addProperty("director", "乔·沃茨");
jsonObject5.addProperty("price", "38");
jsonArray.add(jsonObject5);
JsonObject jsonObject6=new JsonObject();
jsonObject6.addProperty("title", "罗小黑战记");
jsonObject6.addProperty("publishDate", "2019-09-07");
jsonObject6.addProperty("content", "在熙攘的人类世界里,很多妖精隐匿其中,他们与人类相安无事地生活着。猫妖罗小黑因为家园被破坏,开始了它的流浪之旅。这场旅途中惺惺相惜的妖精同类与和谐包容的人类伙伴相继出现,让小黑陷入了两难抉择,究竟何处才是真正的归属 [3] ?");
jsonObject6.addProperty("director", "MTJJ");
jsonObject6.addProperty("price", "38");
jsonArray.add(jsonObject6);
for(int i=0;i<jsonArray.size();i++){
JsonObject jo=jsonArray.get(i).getAsJsonObject();
IndexResponse response=client.prepareIndex("film2", "new")
.setSource(jo.toString(), XContentType.JSON).get();
System.out.println("索引名称:"+response.getIndex());
System.out.println("类型:"+response.getType());
System.out.println("文档ID:"+response.getId());
System.out.println("当前实例状态:"+response.status());
}
}
}
我们用java代码来搞分词搜索;
先定义一个静态常量:
/**
* 条件分词查询
* @throws Exception
*/
@Test
public void search()throws Exception{
SearchRequestBuilder srb=client.prepareSearch("film2").setTypes("new");
SearchResponse sr=srb.setQuery(QueryBuilders.matchQuery("content", "讲述心高气傲").analyzer(ANALYZER))
.setFetchSource(new String[]{"title","price","content"}, null)
.execute()
.actionGet();
SearchHits hits=sr.getHits();
for(SearchHit hit:hits){
System.out.println(hit.getSourceAsString());
}
}
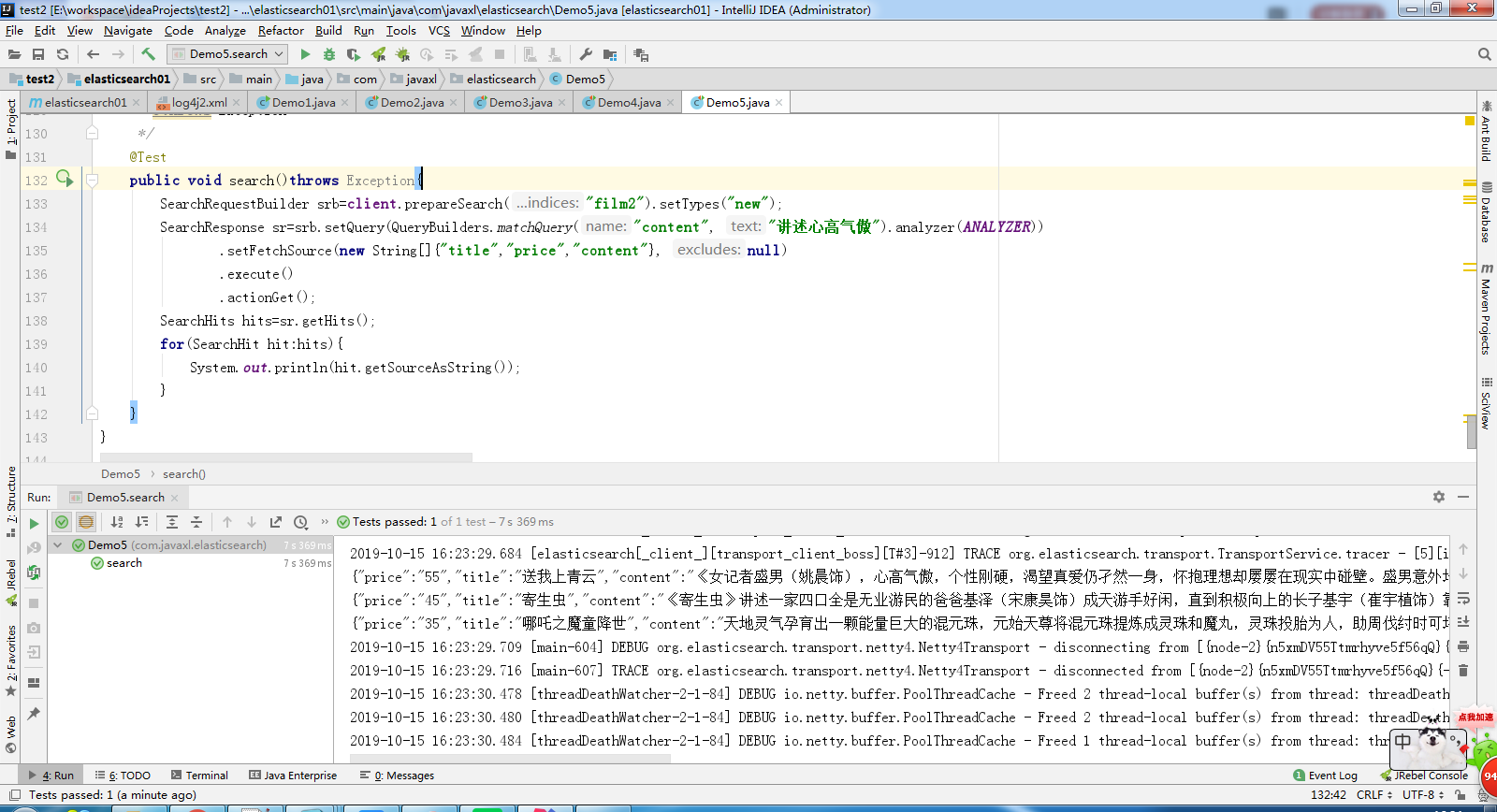
指定了 中文分词,查询的时候 查询的关键字先进行分词 然后再查询,不指定的话,默认标准分词;
这里再讲下多字段查询,比如百度搜索,搜索的不仅仅是标题,还有内容,所以这里就有两个字段;
我们使用 multiMatchQuery 我们看下Java代码:‘’
/**
* 多字段条件分词查询
* @throws Exception
*/
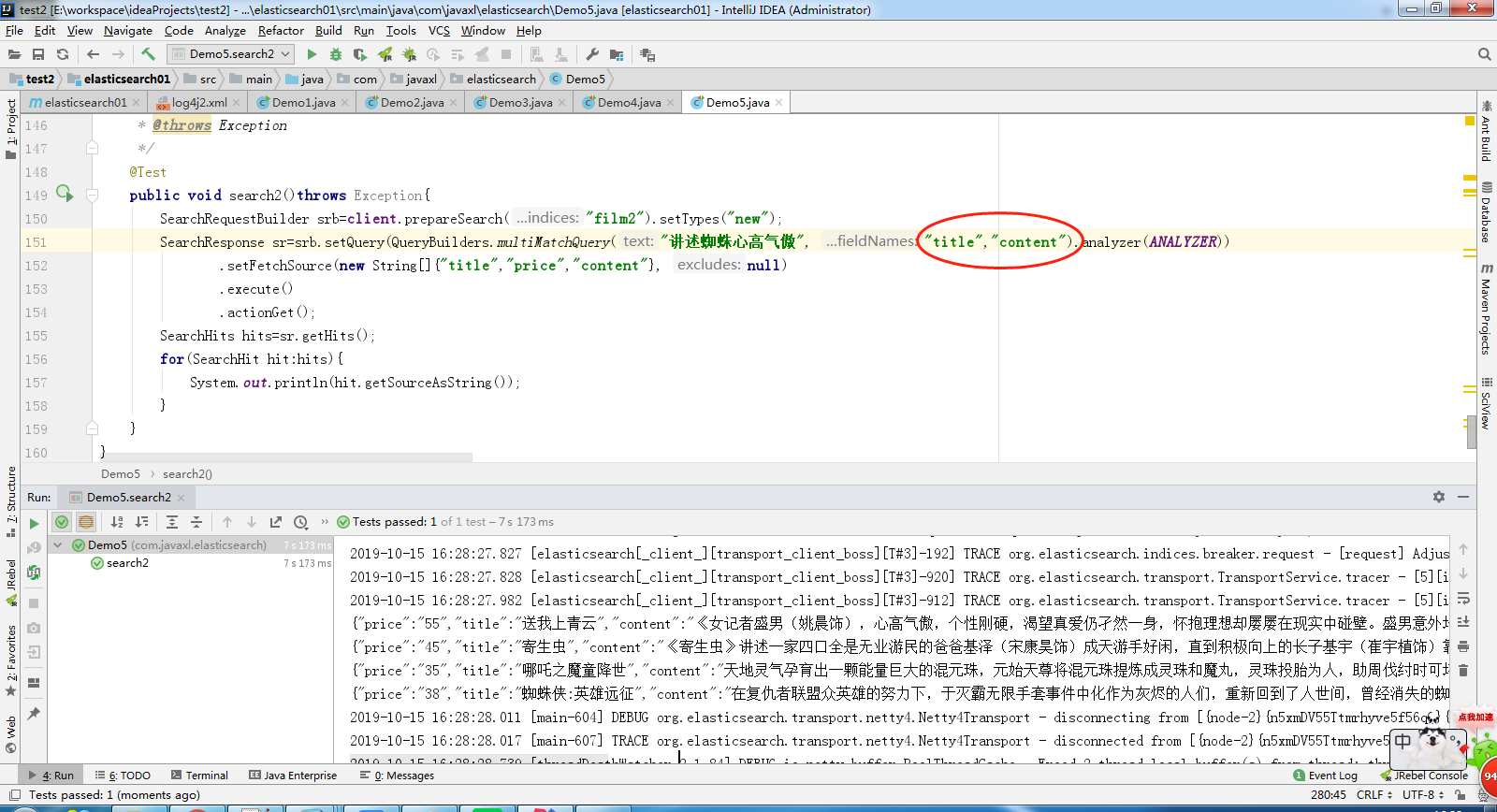
@Test
public void search2()throws Exception{
SearchRequestBuilder srb=client.prepareSearch("film2").setTypes("new");
SearchResponse sr=srb.setQuery(QueryBuilders.multiMatchQuery("讲述蜘蛛心高气傲", "title","content").analyzer(ANALYZER))
.setFetchSource(new String[]{"title","price","content"}, null)
.execute()
.actionGet();
SearchHits hits=sr.getHits();
for(SearchHit hit:hits){
System.out.println(hit.getSourceAsString());
}
}
over......

备案号:湘ICP备19000029号
Copyright © 2018-2019 javaxl晓码阁 版权所有